In a Data Science question, you can add multiple test cases with varying scores to evaluate a candidate’s submission. This is known as partial scoring.
Each test case can be assigned a score. You can follow the provided steps to add partial scoring in your data science question:
1. Add a Data Science question to a test.
Note: You can either select an existing data science question from the library or create a new question.
2. Select the question and click Edit question.
3. Click Data & test cases.

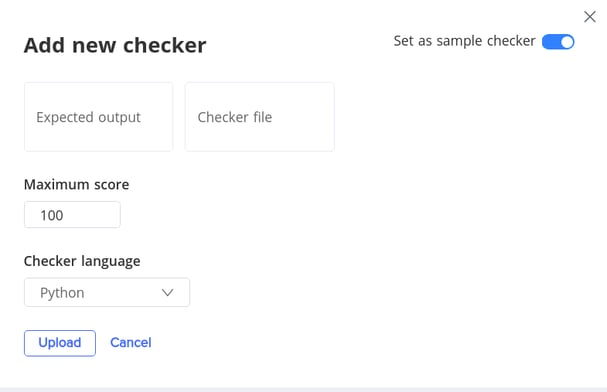
4. In the Checker section, click Add checker file

5. Upload the full expected output (Expected output) and the Checker file. Enter Maximum score for each test case and select the respective Checker language. Then, click Upload.
6. Set as sample checker: You can set a test case (Expected output and Checker) as the sample checker. Once you select a test case as the sample checker, it will be used as a sample Expected output. In other words, when you click COMPILE & TEST, the enabled test case will be used to evaluate the submission. The other test cases will be used to evaluate the submission when SUBMIT is clicked.
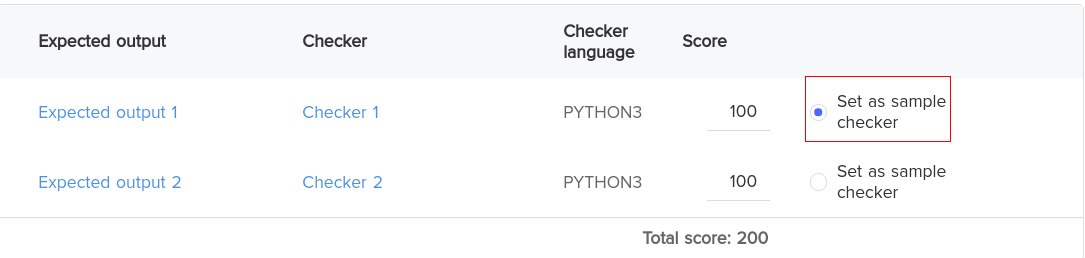
The following example has two test cases. Each test case has a unique evaluation metric to evaluate the submission.
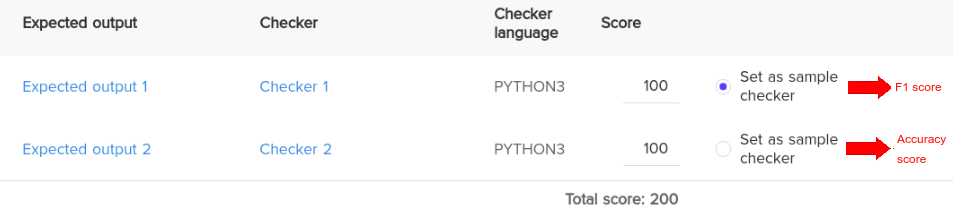
Here, Checker 1 uses F1 score and Checker 2 uses accuracy score as evaluation metric.
When you click COMPILE & TEST, the submission is auto-evaluated against the test case that is set as sample checker, that is, Checker 1. A score with respect to F1 score is generated and displayed.
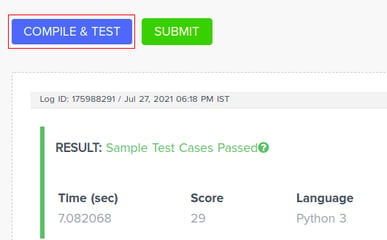
To make a submission, when you click SUBMIT, the submission is auto-evaluated against the other test cases, that is, Checker 2. A final score with respect to accuracy score is generated and displayed.
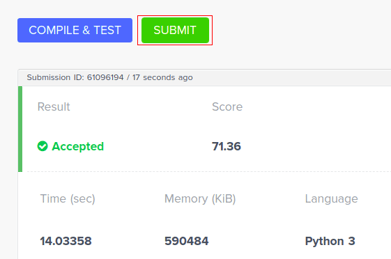
Note: If there are multiple test cases, the final score is the addition of all the scores assigned to each test case. The test case that is set as sample checker will not be considered in this final score.
When you want to change the score for a data science question, you need to update the score on the UI and in the checker files for correct evaluation.
You can implement partial scoring if you want to check a submission with respect to different evaluation metrics. Also, in instances where you have different expected outputs.